TG CHEN
Create value from data, maximise the value of data

Create Your First Project
Start adding your projects to your portfolio. Click on "Manage Projects" to get started


Imbalanced Data Preprocessing in Big Data Approaches
Project type
Group Project
Date
Apr 2023
Location
Nottingham, UK
Skills
- Python (sklearn, PySpark, matplotlib)
- DataBricks: main platform to perform experiments in big datasets
- Microsoft PowerPoint: Presentation
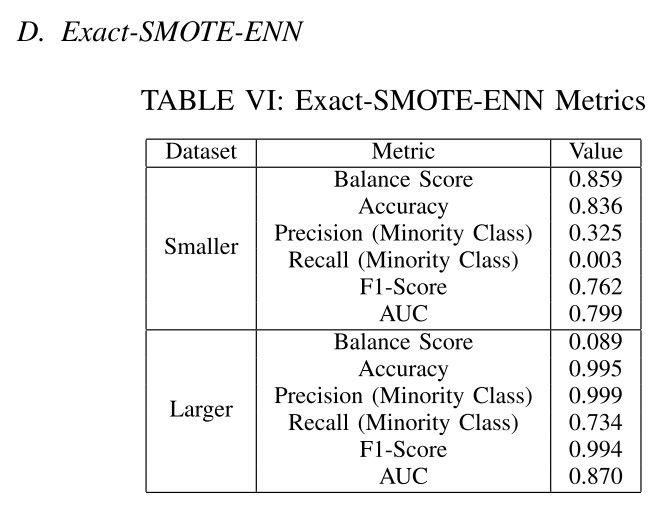
"Exact and Approximate SMOTE Algorithms for Handling Imbalanced Big Data in PySpark"
- Issues: SMOTE, an over-sampling technique, utilises the nearest neighbours algorithm to synthesise new data, while NN doesn’t inherently scale well to big datasets
- Aims: coming up with an efficient implementation of the SMOTE algorithm for big datasets in PySpark
- Developing 4 approaches to address this issue: a local solution, an approximate global solution, an exact global solution, and an exact solution for ENN, a down-sampling variant of SMOTE
- Introducing KDTree to look for the nearest neighbours in NN to reduce time complexity
- Generating a 3.7K words of paper report and a 12-minute presentation